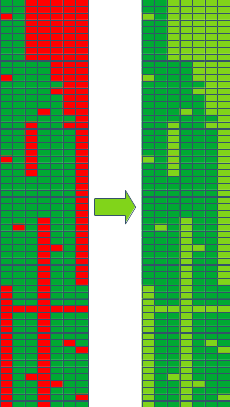
Das Füllen von Lücken in Zeitreihen (zur Motivation hier entlang) hat eine Menge Anforderungen an die Methodik:
Einerseits soll die Qualität der Lückenfüllung natürlich hoch sein, d. h. die gefüllten Werte einer Zeitreihe sollen möglichst nah an den tatsächlich aufgetretenen, aber nicht gemessenen Werten liegen. Das mag trivial klingen, jedoch gibt es einige einfache Methoden, wo beispielsweise bei Temperaturzeitreihen die Lücken mit Jahresmittelwerten ersetzt werden. Damit bleib der Mittelwert der Zeitreihe erhalten, die Werte zu den einzelnen Zeitpunkten sind jedoch grob fehlerhaft.
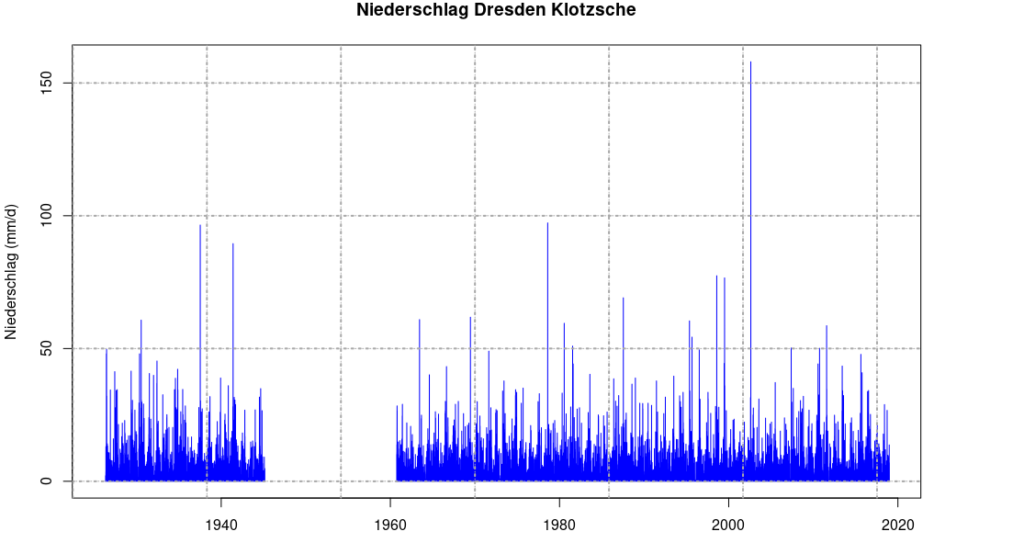
Als nächstes sollte die Methodik damit zurechtkommen, die Lücken sowohl mit wenigen, als auch mit vielen Stützstellen schließen zu können. Stellen wir uns eine Zeitreihe vor, die seit 20 Jahren misst, und wir wollen diese auf eine Länge von 100 Jahre erweitern (ja, das geht 🙂). Zu Beginn des 20. Jhd. gab es nur relativ wenige Messstationen, die als Stützstelle verwendet werden könnten. In den letzten 50 Jahren hingegen ist die Anzahl der Messstationen stark gestiegen. Nun wollen wir sowohl für die weitere als auch die nähere Vergangenheit soviel Informationen (d.h. Stützstellen) verwenden, wie nur irgend möglich, um die bestmögliche Qualität der Lückenfüllung zu erreichen.
Nun ist es so, dass die Zeitreihen, die zur Füllung der Lücken an einer bestimmten Station als Stützstellen verwendet werden sollen, selbst auch Lücken aufweisen. Das bedeutet, dass die Methode mit Lücken in den Stützstellen umgehen können muss. Die allermeisten Methoden können das nicht, so dass die Lücken in den Stützstellen selbst erst mit einer sehr einfachen Methode gefüllt werden müssen, oder die Anzahl der Stützstellen wird drastisch reduziert. Eine weitere Möglichkeit wäre, für jede Lücken eine eigene Liste mit Stützstellen zu erstellen. All dies führt entweder zu einer sehr hohen Rechenzeit oder zu größeren Ungenauigkeit in der Berechnung.
Nicht zuletzt soll die Rechenzeit natürlich erträglich sein. Wenn man für einige Jahrzehnte Stundenwerte meteorologischer Größen aller Stationen in Deutschland rechnet, so kommen einige Hunderttausend Zeitpunkte bei einigen Tausend Zeitreihen heraus. Und jede dieser Zeitreihen hat wieder für sich einige Hundert Zeitreihen als Stützstellen.
Die Methode der Wahl fällt hier auf „Gradient Boosting“, genauer „Gradient Boosted Decision Trees“. Wie der Name sagt, werden hier mit Methoden des maschinellen Lernens Entscheidungsbäume erstellt. Diese bilden die Eigenschaften der Zielgröße, also beispielsweise des Niederschlages an einer bestimmten Stationen, in Abhängigkeit von verschiedenen Stützstellen ab. Diese Stützstellen sind Niederschlagszeitreihen anderer Stationen, aber auch andere Zeitreihen wie die Temperatur, Feuchte, Windgeschwindigkeit oder das Datum gehen in die Entscheidungsbäume mit ein. Der Zusammenhang ist nicht parametrisch und nicht linear, es werden für ein Abbild einige Hundert Bäume mit bis zu zehn Ebenen verwendet.
Die Verwendung von Gradient Boosting löst einige Probleme bereits: Die Berechnung erfolgt extrem schnell, da sie auf Grafikkarten ausführbar ist. Da man mehr Zeitreihen in der gleichen Zeit füllen kann, kann so eine Aufgabe natürlich trotzdem einige Zeit dauern. Die Methodik erlaubt es außerdem, Lücken in den Stützstellen zu verwenden.
Als nächstes sollte Gradient Boosting gleichzeitig mit vielen als auch wenigen Stützstellen zurechtkommen. Das ist nicht grundsätzlich gegeben, hier muss an den zahlreichen Parametern geschraubt werden, um diesen Zustand zu erreichen. Wir nutzen zur Parameteroptimierung eine Kreuzvalidierung mittels genetischem Lernen.
Um aber wirklich gut zu sein braucht es noch etwas mehr. Die Anforderungen sind vielfältig: Die Einzelwerte sollen möglichst gut getroffen werden. Die Statistik der gesamten Zeitreihe soll erhalten werden. Es soll möglich sein, kurze Lücken, vielleicht nur eine Stunde lang, ebenso zu füllen, wie eine Zeitreihe um 100 Jahre in die Vergangenheit zu verlängern. Für all das haben wir ein Framework um die Gradient Boosting Methode herum entwickelt. Das umfasst neben einigen anderen auch state of the art-Methoden wie blending und bagging ebenso wie das Clustern der Lücken, um möglichst effektiv Subzeiträume für die Lückenfüllung zu bestimmen. Mit welcher Qualität bei den unterschiedlichen Szenarien zu rechnen ist, zeigt in Kürze ein anderer Blogpost. Eine Übersicht zur erwarteten Qualität bei einzelnen Lücken gibt es hier in meinem Paper von 2018.