Tl;dnr
Grund die Firma zu gründen war es, einen Service anbieten zu können, den ich selbst gern des öfteren in Anspruch genommen hätte: Vollständige, lückengefüllte Datenreihen von hoher Qualität zu erzeugen.
Wer ein hydrologisches Modell, sei es ein Wasserhaushaltsmodell, ein Niederschlagsabfluss-Modell oder eines zur Hochwasservorhersage, betreiben will, der braucht Daten zum Modellantrieb. Der Abfluss lässt sich nicht berechnen, wenn in der Niederschlagszeitreihe ein Jahr fehlt. In den allermeisten Fällen sind die Anforderungen der Modell an die Daten noch sehr viel höher: Die Modelle laufen nur, wenn die Eingangsdaten lückenlos vorliegen. Das trifft selbstverständlich nicht nur auf die genannten Modelle zu. Pflanzenwachstumsmodelle, Ökosystemmodellierung, Stadtklimamodelle und unzählige weitere mehr haben ähnliche Anforderungen. Gemessene Zeitreihen entsprechen diesen in den wenigsten Fällen: Durch mannigfaltige Ursachen kommt es zu Messausfällen, oder fehlerhafte Messungen müssen aus den Daten entfernt werden.
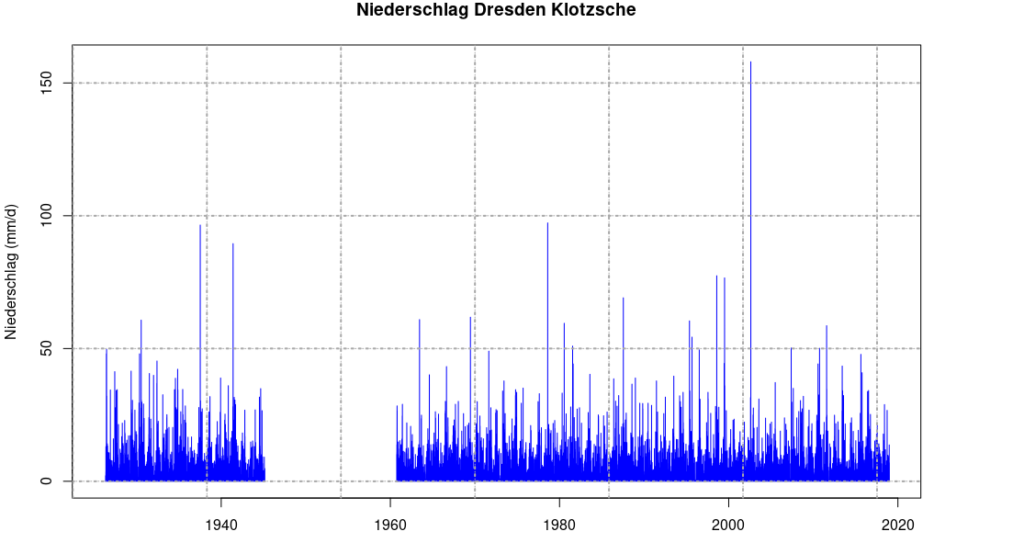
Beispielhaft sei hier die Niederschlagsstation des Deutschen Wetterdienstes in Dresden-Klotzsche gezeigt, die zwischen den Jahren 1945 und 1960 keine Daten aufweist.
Um dennoch vollständige Zeitreihen zu erhalten, wird in solchen Fällen häufig auf die nächstgelegene Station mit Daten zurückgegriffen. Das führt zu inhomogenen Zeitreihen, da die umliegenden Stationen andere statistische Eigenschaften aufweisen, wie einen anderen Mittelwert, andere Extreme und verschiedene Häufigkeit von Niederschlagstagen. Es gibt weitere Verfahren, wie räumliche Interpolation, (multiple-) lineare Regression oder die Verwendung von Reanalysedaten, die alle unterschiedlich aufwendig sind und jeweils ihre eigenen Fehler haben. Für was auch immer man sich entscheidet, am Ende hat man viel Zeit in die Lückenfüllung gesteckt oder hat eine fehlerbehaftete Zeitreihe oder, im ungünstigen Fall, beides.
In meinem eigenen Fall brauchte ich für meine Arbeit Stundenwerte für Temperatur, Windgeschwindigkeit und relativer Feuchte. Im Vergleich zu Tageswerten haben Stundenwerte drei negative Eigenschaften: Die Zeitreihen sind kürzer, es gibt insgesamt deutlich weniger Zeitreihen und es gibt erheblich mehr Lücken. Außerdem kam es hier besonders darauf an, dass die lückengefüllten Daten einen möglichst kleinen Fehler aufweisen sollten. Es ging also nicht darum, ein einigermaßen befriedigendes Ergebnis zu erzielen, sondern das bestmögliche. Bei mehreren hundert Zeitreihen mit jeweils mehreren hunderttausend Zeitschritten erwiesen sich die vorhandenen Methoden als nicht umsetzbar. Einerseits war die Rechenzeit exorbitant hoch, andererseits die Qualität nicht ausreichend. Es galt also, neue Methoden zu entwickeln, die beiden Ansprüchen genügt: Einen möglichst kleinen Fehler in einer möglichst geringen Rechenzeit zu realisieren. Wie und in welchen Bereichen das gelungen ist, wird in den nächsten Blogposts erläutert.