Tl;dnr
The reason for founding the company was to be able to offer a service that I myself would have liked to use more often: to generate complete, gap-filled data series of high quality.
If you want to run a hydrological model, be it a water balance model, a rainfall-runoff model or a flood forecasting model, you need data to drive the model. Runoff cannot be calculated if a year is missing from the precipitation time series. In the vast majority of cases, the data requirements of the model are much higher: the models only run if the input data is available without gaps. Of course, this does not only apply to the models mentioned. Plant growth models, ecosystem modelling, urban climate models and countless others have similar requirements. Measured time series rarely fulfil these requirements: Measurement failures occur for a variety of reasons, or incorrect measurements have to be removed from the data.
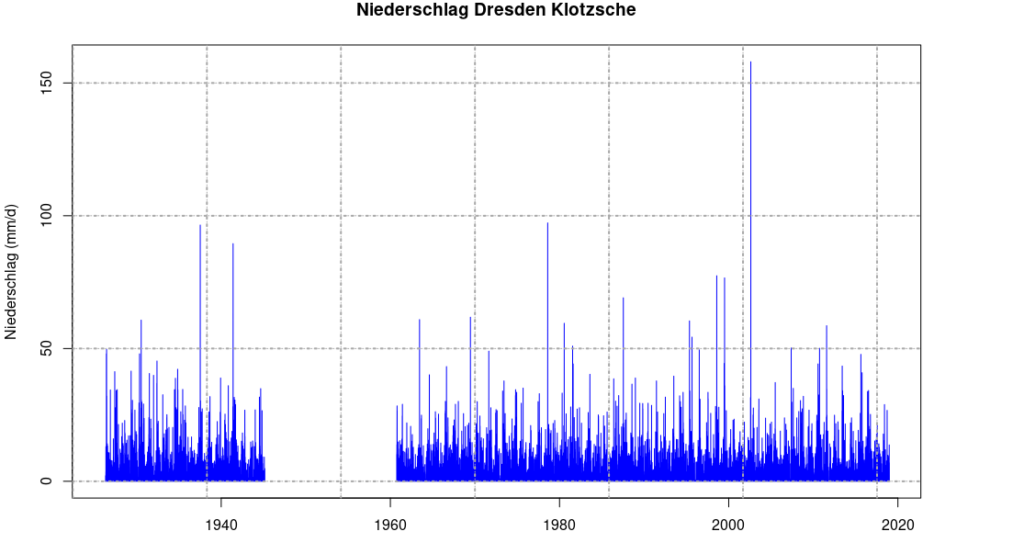
The precipitation station of the German Weather Service in Dresden-Klotzsche, which has no data between 1945 and 1960, is shown here as an example.
In order to obtain complete time series, the nearest station with data is often used in such cases. This leads to inhomogeneous time series, as the neighbouring stations have different statistical properties, such as a different mean value, different extremes and different frequencies of precipitation days. There are other methods, such as spatial interpolation, (multiple) linear regression or the use of reanalysis data, all of which vary in complexity and have their own errors. Whatever you choose, in the end you will have spent a lot of time filling in the gaps or you will have an error-prone time series or, in the worst case, both.
In my own case, I needed hourly values for temperature, wind speed and relative humidity for my work. Compared to daily values, hourly values have three negative characteristics: The time series are shorter, there are significantly fewer time series overall and there are considerably more gaps. In addition, it was particularly important here that the gap-filled data should have as small an error as possible. The aim was therefore not to achieve a reasonably satisfactory result, but to achieve the best possible result. With several hundred time series, each with several hundred thousand time steps, the existing methods proved to be unfeasible. On the one hand, the computing time was exorbitantly high, on the other hand, the quality was insufficient. It was therefore necessary to develop new methods that met both requirements: To realise the smallest possible error in the shortest possible computing time. How and in which areas this was achieved will be explained in the next blog posts.