Zeitreihen auffüllen und verlängern
Kurzbeschreibung
Das Auffüllen und Verlängern von Zeitreihen ist ein Verfahren, das darauf abzielt, Lücken in meteorologischen Messreihen zu schließen und diese Reihen gegebenenfalls zu verlängern. Ziel ist es, möglichst vollständige und kontinuierliche Datensätze für verschiedene meteorologische Parameter wie Temperatur, Niederschlag oder Windgeschwindigkeit bereitzustellen.
Warum Lücken füllen?
Meteorologische Messreihen weisen häufig Lücken auf, verursacht durch technische Ausfälle, Wartungsarbeiten oder andere Störungen im Messbetrieb. Die meisten Zeitreihen beginnen nach dem Start des Untersuchungszeitraumes oder enden vorzeitig. Für viele Anwendungen – wie die Klimaanalyse, Trendbestimmung oder Modellierung – sind jedoch vollständige Zeitreihen notwendig. Das Auffüllen und Verlängern der Zeitreihen ermöglicht es, diese Anforderungen zu erfüllen und die Aussagekraft und Verwendbarkeit der Daten zu erhöhen. Besonders wichtig sind vollständige Zeitreihen als Ausgangsdaten für räumliche Interpolation: Das Nutzen von unvollständigen Zeitreihen führt zu räumlich/zeitlichen Brüchen im Rasterprodukt. Werden nur vollständige gemessene Zeitreihen für ein Rasterprodukt verwendet, so sinkt die Datenbasis deutlich und die Qualität der Rasterdaten sinkt stark.
Vorgehen
Dabei werden fehlende Werte in bestehenden Messreihen mithilfe Informationen benachbarter Stationen geschätzt. Zum Einsatz kommen Verfahren des maschinellen Lernens (Gradient Boosting), wodurch die Schätzfehler auf ein Minimum reduziert werden können.
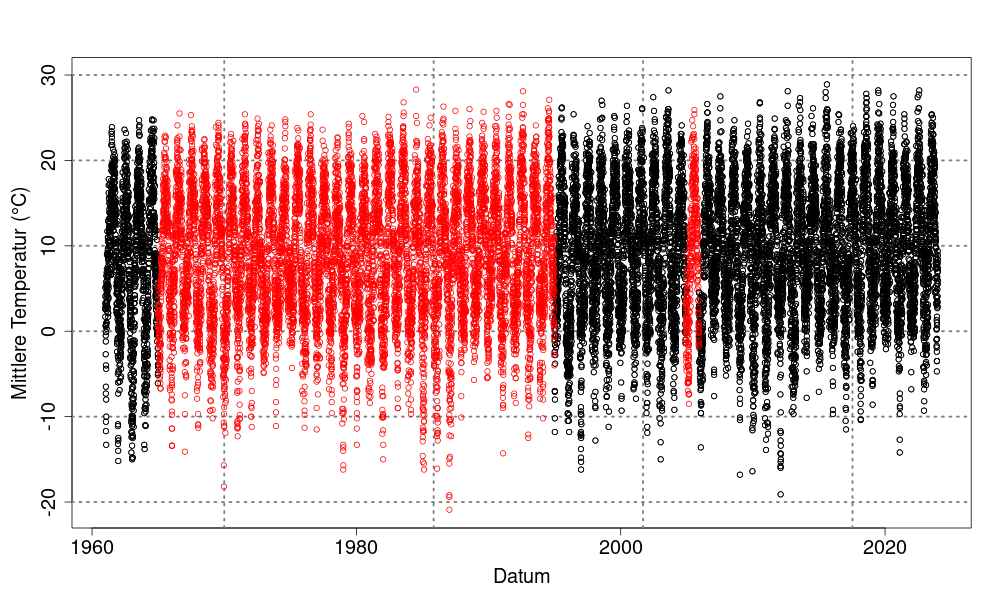
Qualität und Eigenschaften
Die Qualität der Lückenfüllung wird von uns durch unabhängige Validierungsverfahren wie die Kreuzvalidierung überprüft. Dabei werden bekannte Werte temporär entfernt, mit der gewählten Methode rekonstruiert und mit den Originalwerten verglichen. Die Güte der Methode lässt sich anhand statistischer Kennzahlen wie dem mittleren Fehler oder der Standardabweichung bewerten. Ein hochwertiges Verfahren liefert möglichst genaue Schätzungen und erhält die statistischen Eigenschaften der Originaldaten.
Referenzen
Landesanstalt für Umwelt Baden-Württemberg (LUBW):
Klimaatlas Baden-Würtemberg, lückenlose Tagesdaten für Baden-Württemberg und Umgebung 1961-2023
Landesamt für Umwelt, Landwirtschaft und Geologie (LfULG Sachsen):
Referenzdatensatz 3.0 im ReKIS, lückenlose Tagesdaten für Sachsen, Sachsen-Anhalt, Thüringen, Brandenburg und Umgebung 1961-2023
Staatsbetrieb Sachsenforst (SBS):
Lückenlose Tagesdaten der meteorologischen Daten der Waldstandorte 1961-2023
Literatur
Körner, P., Kronenberg, R., Genzel, S., Bernhofer, C., 2018. Introducing Gradient Boosting as a universal gap filling tool for meteorological time series. Meteorologische Zeitschrift 369–376. https://doi.org/10.1127/metz/2018/0908
Erstellen von Rasterdatensätzen
Beschreibung
Das Erstellen von Rasterdatensätzen aus meteorologischen Stationsdaten ist ein Prozess, bei dem punktuelle Messwerte von Wetterstationen in flächendeckende, regelmäßig aufgelöste Datenfelder (Raster) überführt werden. Diese Rasterdatensätze bilden die räumliche Verteilung meteorologischer Größen über ein bestimmtes Gebiet ab.
Warum Rasterdaten?
Stationsdaten liefern nur punktuelle Informationen, während für viele Anwendungen – etwa hydrologische Modellierung, landwirtschaftliche Planung oder Klimafolgenabschätzung – flächendeckende Informationen benötigt werden. Rasterdatensätze ermöglichen Analysen und Visualisierungen auf regionaler oder nationaler Ebene und sind unverzichtbar für die Verknüpfung meteorologischer Daten mit anderen Geoinformationen.
Vorgehen
Hierzu werden verschiedene räumliche Interpolationsmethoden eingesetzt, wie beispielsweise Kriging oder Splines. Diese Methoden nutzen die Werte der umliegenden Stationen, um für jede Rasterzelle einen plausiblen Wert zu berechnen. So entstehen kontinuierliche Felder für Parameter wie Temperatur, Niederschlag, Windgeschwindigkeit oder andere meteorologische Größen.
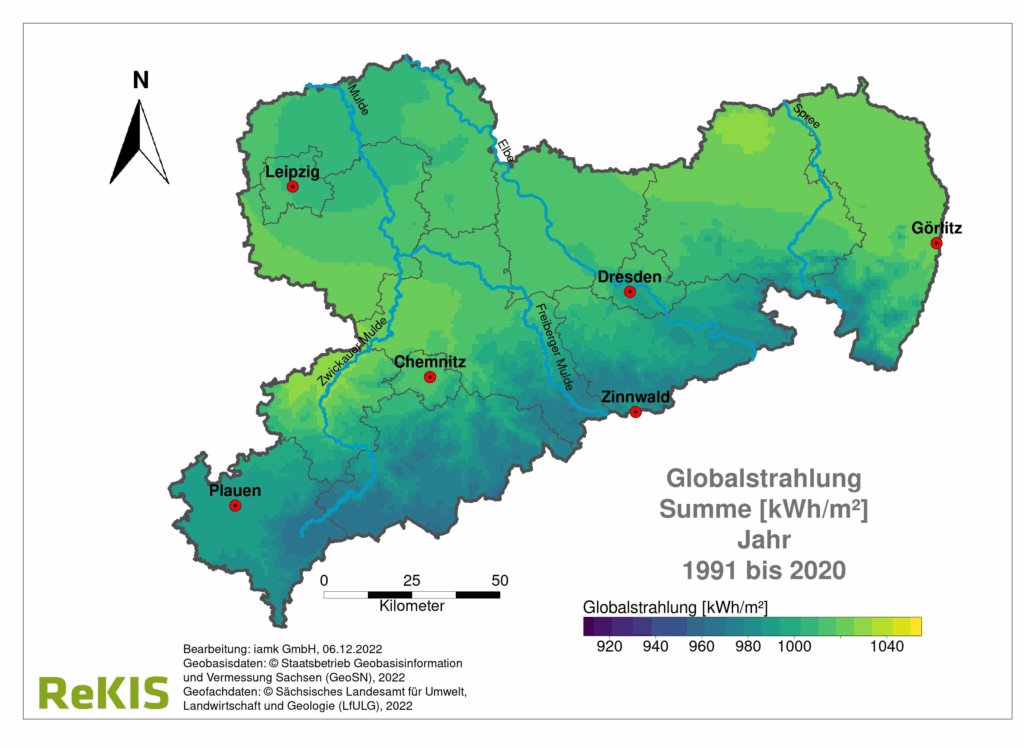
Qualität und Eigenschaften
Die Qualität der erzeugten Rasterdatensätze wird von uns durch Validierungsverfahren wie Kreuzvalidierung überprüft. Dabei werden einzelne Stationen aus dem Interpolationsprozess ausgeschlossen, die Werte an diesen Punkten berechnet und mit den tatsächlichen Messwerten verglichen. Die Genauigkeit der Interpolation hängt von der Stationsdichte, der gewählten Methode und der räumlichen Variabilität der meteorologischen Größe ab. Hochwertige Rasterdatensätze zeichnen sich durch möglichst geringe Abweichungen zwischen berechneten und gemessenen Werten aus und bilden die räumlichen Strukturen der meteorologischen Größen realitätsnah ab. Bei der mittleren Temperatur wird beispielsweise ein Bestimmtheitsmaß R² von 0,992 und ein mittlerer absoluter Fehler von 0,52°C erreicht.
Referenzen
Landesanstalt für Umwelt Baden-Württemberg (LUBW):
Klimaatlas Baden-Würtemberg, lückenlose Rasterdaten für Baden-Württemberg und Umgebung 1961-2023
Landesamt für Umwelt, Landwirtschaft und Geologie (LfULG Sachsen):
Referenzdatensatz 3.0 im ReKIS, lückenlose Rasterdaten für Sachsen, Sachsen-Anhalt, Thüringen, Brandenburg und Umgebung 1961-2023
Stündliche Niederschlagsraster ab 1951
Beschreibung
Stündliche Rasterdaten zum Niederschlag stehen durch Radarmessungen oder die räumliche Interpolation von stündlichen Stationsdaten erst seit den frühen 2000er Jahren zur Verfügung. Dank eigens entwickelter Methoden ist es nun jedoch möglich, stündliche Niederschlagsraster bereits ab dem Jahr 1951 zu generieren.
Warum stündliche Niederschlagsraster?
Stündliche Niederschlagsraster bieten zahlreiche Vorteile:
- Räumliche Konsistenz: Die hohe räumliche Auflösung erlaubt regionale Vergleiche und eine bessere Einschätzung lokaler Risiken.
- Feinere zeitliche Auflösung: Sie ermöglichen eine detaillierte Analyse von Niederschlagsereignissen, insbesondere von Starkregen, die in Tageswerten nicht erkennbar wären.
- Verbesserte Modellierung: Hydrologische und klimatologische Modelle profitieren von den präzisen Eingangsdaten, etwa für Hochwasservorhersagen oder die Bewertung von Extremereignissen.
- Lückenlose Zeitreihen: Sie ermöglichen die Untersuchung von Trends und Veränderungen im Niederschlagsverhalten über viele Jahrzehnte hinweg.
Vorgehen
Zur Erstellung der stündlichen Niederschlagsraster werden zunächst die täglichen Niederschlagswerte mithilfe eines Modells (Gradient Boosting) auf Stundenwerte disaggregiert. Hierbei werden gemessene stündliche Werte anderer meteorologischer Größen, die ab 1951 verfügbar sind, in Beziehung zum stündlichen Niederschlag gesetzt.
Zusätzlich wird ein weiteres Modell eingesetzt, das die Anzahl der Niederschlagsstunden pro Tag in Abhängigkeit von denselben Prädiktoren erlernt. Für den gewünschten Zeitraum werden zunächst Raster der meteorologischen Größen in stündlicher Auflösung berechnet. Hier kommen die oben beschriebenen Methoden und Produkte zum Einsatz, um die stündlichen Niederschlagsraster zu erzeugen. Diese Raster dienen als Prädiktoren zur Anwendung der vorher trainierten Modelle.
Das Ergebnis sind Rasterdaten mit einer räumlichen Auflösung von 100 Metern und einer zeitlichen Auflösung von einer Stunde – und das bereits ab 1951. Diese Kombination aus hoher Auflösung und langer Zeitreihe stellt ein Novum dar.
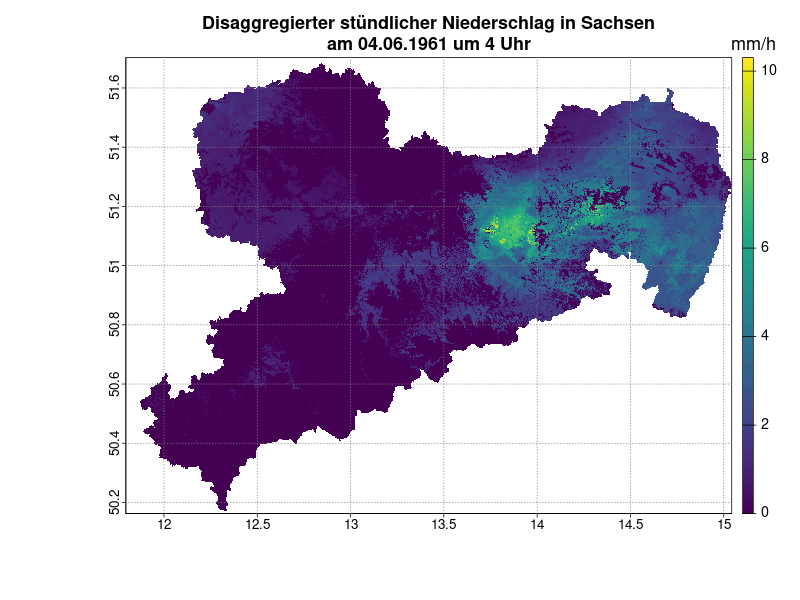
Qualität und Eigenschaften
Die statistischen Eigenschaften der ursprünglichen Daten, wie die Verteilung des Niederschlags über den Tag und die Häufigkeit von Niederschlagsereignissen, bleiben weitestgehend erhalten. Auch die räumliche Konsistenz wird gewährleistet. Im Gegensatz zu anderen Methoden werden die tatsächlichen Ereignisse besser abgebildet. Zusätzlich sind die Daten klimatologisch konsistent (raumdiskrete Jahressumme und Trend).
Die Qualität der Ergebnisse ist durch einen Heidke Skill Score von über 0,6 und eine Korrelation im Bereich von 0,6 in der Kreuzvalidierung belegt – Werte, die bisher von keiner anderen Methode erreicht wurden.
Referenzen
Landesamt für Umwelt, Landwirtschaft und Geologie (LfULG Sachsen):
Räumliche Disaggregation des Niederschlages im ReKIS, lückenlose Stundenraster für Sachsen 1961-2023 (Veröffentlichung in Vorbereitung)
Nebel und Nebelniederschlag
Beschreibung
Die Berechnung von Nebel und Nebeldeposition bestimmt das Vorkommen von Nebel am Boden sowie die Ablagerung von Nebeltröpfchen (Nebeldeposition) aus der Atmosphäre auf Oberflächen. Dabei wird insbesondere die flüssige Wassergehaltsmenge (liquid water content, lwc) in der bodennahen Luft berechnet und als Indikator für das Vorhandensein von Nebel genutzt. Das Produkt basiert auf meteorologischen Messdaten wie Temperatur, relativer Luftfeuchtigkeit und Geländehöhe, die in stündlicher Auflösung ausgewertet werden, um das Auftreten und die Intensität von Nebel räumlich und zeitlich zu erfassen.
Warum Nebel?
Das Monitoring von Nebel und Nebeldeposition ist aus mehreren Gründen bedeutsam:
- Nebeldeposition kann technische Anlagen (z. B. Windkraftanlagen) beeinträchtigen und Vegetationsschäden verursachen, insbesondere durch Eisnebel
- Nebel beeinträchtigt die Sicht und stellt ein Risiko für den Straßen-, Luft- und Schiffsverkehr dar.
- In bestimmten Ökosystemen, wie Nebelwäldern, ist Nebel eine wichtige Wasserquelle und beeinflusst die Vegetation.
- Nebel kann als alternative Wasserressource genutzt werden, beispielsweise durch Nebelkollektoren.
Vorgehen
Das Produkt liefert Informationen darüber, wann und wo Nebel auftritt und wie viel flüssiges Wasser dabei in der Luft enthalten ist. Nebel wird als eine Ansammlung sehr kleiner Wassertröpfchen (Durchmesser etwa 3–50 μm) in der bodennahen Atmosphäre definiert, die die Sichtweite auf unter einen Kilometer reduzieren können. Die Nebeldeposition beschreibt die Ablagerung dieser Tröpfchen auf Oberflächen, was beispielsweise für die Wasserbilanz von Ökosystemen oder technische Anwendungen wie Nebelkollektoren relevant ist. Die zentrale Kenngröße ist der flüssige Wassergehalt (lwc) pro Kubikmeter Luft, der mit Hilfe physikalischer Modelle aus Messdaten berechnet wird.
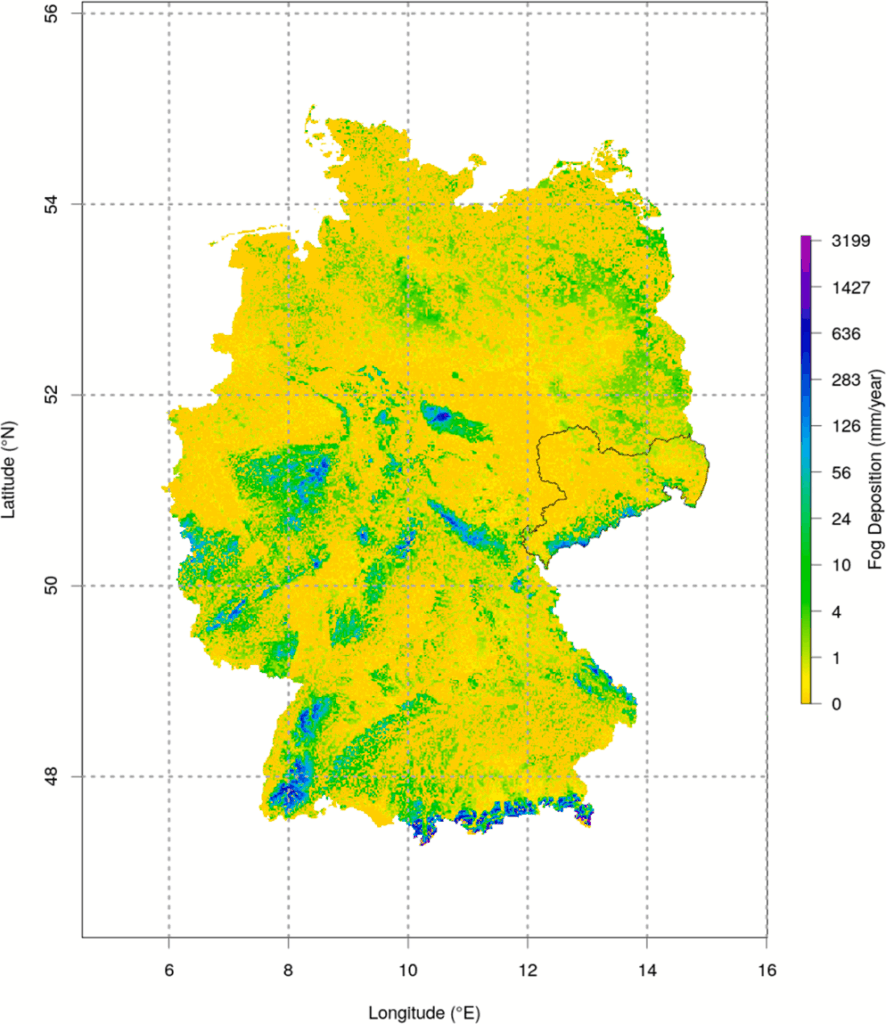
Qualität und Eigenschaften
Das Produkt zeichnet sich durch folgende Eigenschaften aus:
- Grenzen der Messung: Direkte lwc-Messungen sind selten und aufwändig, weshalb häufig auf abgeleitete Größen (z. B. aus Sichtweitenmessungen) zurückgegriffen wird. Diese Ableitungen sind jedoch mit Unsicherheiten behaftet und standortspezifisch
- Physikalisch fundierte Berechnung: Die Bestimmung des Nebelauftretens und der Nebeldeposition erfolgt auf Basis von Temperatur, relativer Feuchte und Geländehöhe. Die Berechnung des lwc erfolgt mit stündlicher Auflösung und räumlicher Interpolation.
- Korrektur von Messfehlern: Da Messungen von Temperatur und Feuchte fehlerbehaftet sein können (z. B. durch Sensoralterung oder Kalibrierungsprobleme), werden Korrekturverfahren angewendet, um die Datenqualität zu verbessern.
- Validierung: Die Modellierungsergebnisse werden mit Messungen von Sichtweite und lwc an Referenzstationen verglichen. Die Güte der Nebelerkennung wird mit Skill Scores (z. B. Heidke Skill Score) bewertet und zeigt eine hohe Übereinstimmung zwischen Modell und Beobachtung.
- Hohe zeitliche und räumliche Variabilität: Nebel und seine Wassergehalte sind sehr variabel, sowohl zeitlich (z. B. zwischen einzelnen Stunden) als auch räumlich (z. B. zwischen verschiedenen Standorten und Höhenlagen).
Referenzen
Landesamt für Umwelt, Landwirtschaft und Geologie (LfULG Sachsen):
Nebeldeposition Sachsen im ReKIS, tägliche Rasterdaten in 100 Metern Auflösung für Sachsen, 1961-2020
Literatur
Körner, P., Kalaß, D., Kronenberg, R., Bernhofer, C., 2020. REAL-Fog: A simple approach for calculating the fog in the atmosphere at ground level. Meteorologische Zeitschrift. https://doi.org/10.1127/metz/2019/0976
Körner, P., Rico, K., Gliksman, D., Christian, B., 2021. REAL-Fog Part 2: A novel approach to calculate high resoluted spatio-temporal Fog Deposition: a daily fog deposition data set for entire Germany for 1949-2018. Journal of Hydrology 126360. https://doi.org/10.1016/j.jhydrol.2021.126360
Webseite
Täglich aktualisierte Stundenraster mit Validierung:
Täglich aktualisierte 10-Minuten-Raster: